Computer Vision ได้กลายเป็นสาขาหลักของปัญญาประดิษฐ์ที่เน้นการให้คอมพิวเตอร์สามารถตีความและเข้าใจข้อมูลเชิงภาพในระดับที่เปรียบได้กับการรับรู้ของมนุษย์ วิวัฒนาการของสาขานี้สะท้อนให้เห็นถึงการเคลื่อนผ่านจากการออกแบบฟีเจอร์โดยมนุษย์ ไปสู่การเรียนรู้คุณลักษณะจากข้อมูลภาพโดยอัตโนมัติ และในปัจจุบันกำลังเปลี่ยนผ่านสู่สถาปัตยกรรมที่อาศัยกลไกความสนใจ (Attention Mechanisms) อย่าง Vision Transformer ซึ่งเป็นการผสานแนวคิดจากการประมวลผลภาษาธรรมชาติเข้ากับการประมวลผลภาพ
จาก Feature Engineering & End-to-End Representation Learning
จากกระบวนการออกแบบฟีเจอร์โดยมนุษย์ การพัฒนาได้เปลี่ยนผ่านสู่การเรียนรู้แบบ end-to-end ที่สามารถสกัดฟีเจอร์โดยตรงจากข้อมูลภาพดิบอย่างเป็นระบบ แนวทางนี้เปิดโอกาสให้โมเดลสามารถเรียนรู้ตัวแทนข้อมูล (Representations) ที่เหมาะสมที่สุดกับงานที่กำหนดได้โดยไม่ต้องอาศัยการออกแบบเชิงวิศวกรรมเฉพาะทาง ส่งผลให้เกิดการเพิ่มขึ้นอย่างมีนัยสำคัญในด้านความแม่นยำและการ generalize ข้ามโดเมน ในหลาย ๆ กรณี ระบบดังกล่าวยังสามารถปรับตัวต่อข้อมูลหลากหลายประเภทได้ดีขึ้น ทั้งในแง่ของลำดับชั้นเชิงพื้นที่ (Spatial Hierarchy) และบริบทเชิงความหมาย (Semantic Context)
ยุคแรกของ Computer Vision ประกอบด้วยการดึงฟีเจอร์ด้วยมือ (Handcrafted Feature Extraction) โดยใช้เทคนิคอย่าง Histogram of Oriented Gradients (HOG), Scale-Invariant Feature Transform (SIFT), และ Speeded-Up Robust Features (SURF) ซึ่งเป็นกระบวนการทางเรขาคณิตและเชิงแสงในการแยกลักษณะเด่นเฉพาะของวัตถุเพื่อการจำแนก แนวทางนี้ยังคงต้องพึ่งพาการออกแบบจากผู้เชี่ยวชาญ และขาดความสามารถในการประยุกต์ใช้กับสถานการณ์ทั่วไปได้อย่างยืดหยุ่น (Generalization)
โมเดลแบบดั้งเดิม เช่น SVM หรือ k-NN ถูกใช้เป็นตัวจำแนกบนฟีเจอร์เหล่านี้ อย่างไรก็ตาม ความสามารถของระบบถูกจำกัดอยู่ที่ความสมบูรณ์ของฟีเจอร์ ซึ่งนำไปสู่ความต้องการแนวทางที่สามารถเรียนรู้ตัวแทน จากข้อมูลดิบได้โดยตรง ซึ่งถูกเติมเต็มด้วยการมาของ Deep Learning
พื้นฐานเชิงคณิตศาสตร์ของ Convolutional Neural Network
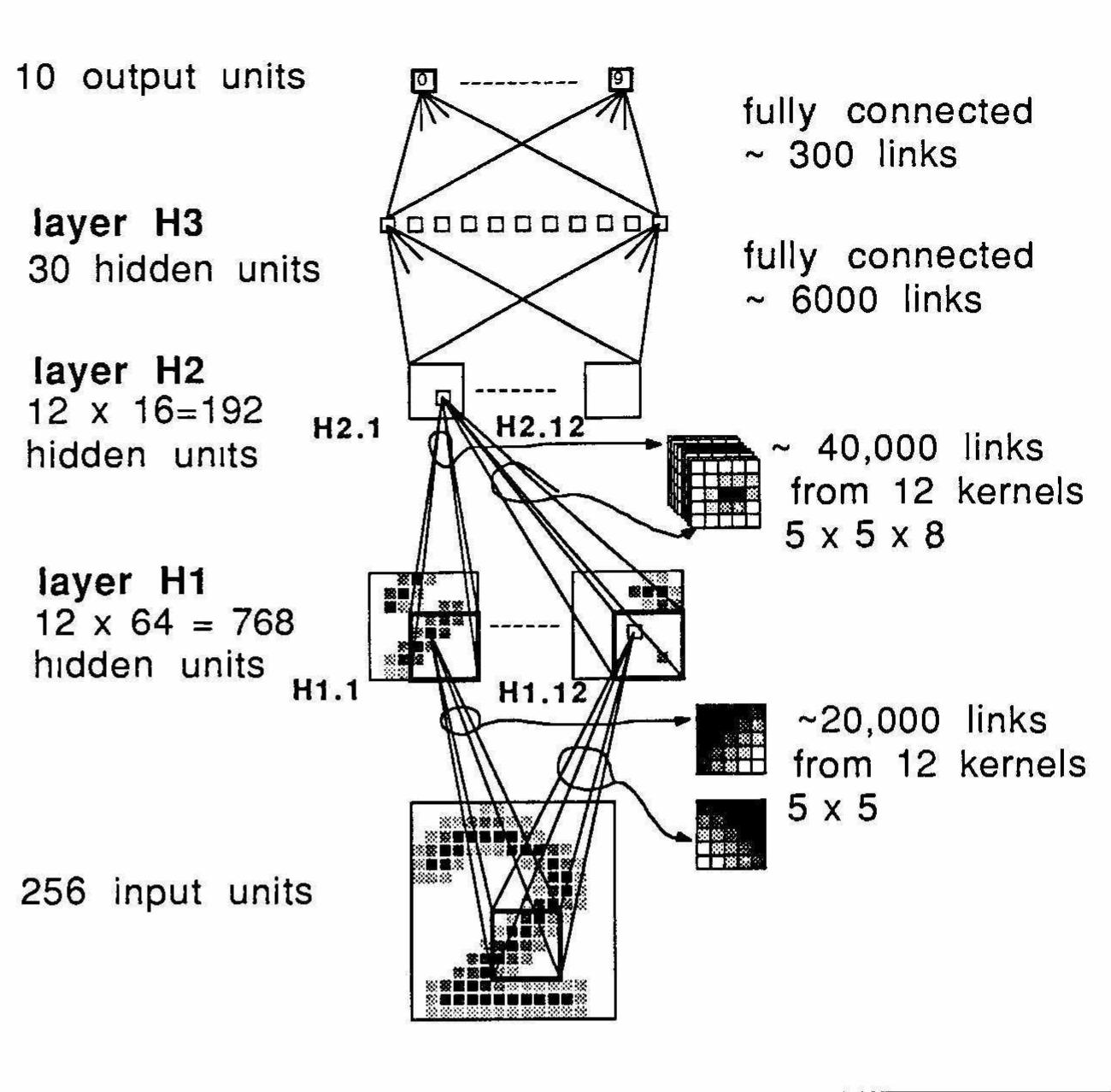
ภาพที่ 1 สถาปัตยกรรม Convolutional Neural Network รุ่นแรกของ LeCun ชื่อว่า LeNet-1 ใช้สำหรับจำแนกตัวเลขที่เขียนด้วยลายนิ้วมือ
(ที่มา: LeCun et al. (1989). Backpropagation applied to handwritten zip code recognition.)
Convolutional Neural Network (CNN) ถือเป็นการเปลี่ยนแปลงเชิงโครงสร้างที่สำคัญ โดยสถาปัตยกรรมนี้สามารถเรียนรู้ลักษณะเฉพาะของภาพในหลายระดับชั้นผ่านการคูณเชิงจุด (Dot Product) ระหว่างฟิลเตอร์และส่วนย่อยของภาพ ซึ่งสามารถนิยามเชิงสมการได้ดังนี้
สมการที่ 1 Convolution (Discrete Convolution Equation)
โดยที่
คือ Input (เช่น ภาพหรือ Feature Map)
คือ Kernel (หรือ Filter)
คือ ตำแหน่งพิกเซลใน output feature map
CNN ยังสามารถซ้อนเลเยอร์ได้อย่างลึก ซึ่งทำให้สามารถเรียนรู้ฟีเจอร์ที่มีความซับซ้อนเชิงนามธรรม เช่น โครงสร้างใบหน้า ลวดลายทางสถาปัตยกรรม หรือแม้แต่สัญลักษณ์ทางภาษาได้อย่างมีประสิทธิภาพ
ขีดจำกัดของ CNN และการมาถึงของ Vision Transformer
แม้ Convolutional Neural Networks จะประสบความสำเร็จอย่างโดดเด่นในหลากหลายงานด้านการประมวลผลภาพ แต่ยังมีข้อจำกัดสำคัญในด้านการเรียนรู้ความสัมพันธ์ระยะไกล (Long-Range Dependencies) เนื่องจากโครงสร้างของ Receptive Field ในแต่ละชั้นนั้นขยายตัวอย่างค่อยเป็นค่อยไปตามลำดับชั้นของเครือข่าย
Vision Transformer (ViT) แก้ไขข้อจำกัดของ CNN ในการจับความสัมพันธ์ระยะไกล โดยใช้กลไก Self-Attention ซึ่งสามารถเชื่อมโยงข้อมูลระหว่างตำแหน่งต่าง ๆ ทั่วทั้งภาพได้อย่างไม่มีข้อจำกัดด้านพื้นที่ ViT แปลงภาพอินพุตให้เป็นลำดับของ patch ขนาดคงที่ เช่น 16×16 พิกเซล จากนั้นนำแต่ละ patch ผ่านกระบวนการ Linear Projection เพื่อแปลงเป็นเวกเตอร์เชิงคุณลักษณะ และผนวกเข้ากับ Positional Encoding เพื่อรักษาข้อมูลตำแหน่ง ก่อนส่งเข้าสู่เครือข่าย Transformer Encoder ที่ประกอบด้วยหลายชั้นของกลไก Self-Attention และ Feed-Forward Network
กลไก Self-Attention เชิงคณิตศาสตร์
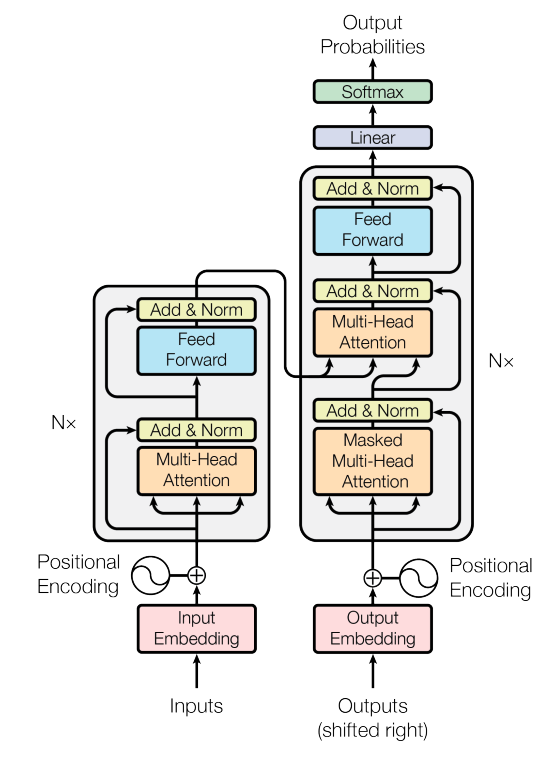
ภาพที่ 2 โครงสร้างของ Transformer Architecture
(ที่มา: Vaswani et al. (2017). Attention is All You Need.)
Self-Attention เป็นกลไกที่ประเมินความสำคัญเชิงสัมพันธ์ระหว่างตำแหน่งต่าง ๆ ของ Input Sequence ผ่านสมการ ดังต่อไปนี้
สมการที่ 2 Scaled Dot-Product Attention
โดยที่ , , คือ Query, Key และ Value Matrix ที่ได้จาก Linear Transformation ของ patch Embeddings ตามลำดับ การออกแบบนี้ช่วยให้ ViT เข้าใจภาพทั้งใบในระดับ Global Context ได้โดยไม่ต้องพึ่งพาโครงสร้างเชิงเรขาคณิตแบบ CNN
การเลือกใช้งานระหว่าง CNN และ ViT
การตัดสินใจเลือกสถาปัตยกรรมขึ้นกับหลายปัจจัย ทั้งขนาดของ Dataset ความซับซ้อนของงานและทรัพยากรทางคอมพิวเตอร์ที่มีอยู่
CNN
จุดแข็ง: ประสิทธิภาพดีภายใต้สภาพแวดล้อมที่ข้อมูลมีจำกัด เหมาะกับการประยุกต์บนอุปกรณ์ Edge มีความสามารถในการตีความภาพในเชิงโครงสร้างที่ชัดเจน
ข้อจำกัด: ยังขาดความสามารถในการทำความเข้าใจภาพในระดับบริบทเชิงองค์รวม (Holistic Context) และเมื่อเพิ่มขนาดโมเดล (Scaling) มักพบปัญหาผลตอบแทนถดถอย (Diminishing Returns)
ViT
จุดแข็ง: เหมาะกับระบบที่มีข้อมูลปริมาณมาก ความสามารถด้าน Transfer Learning สูง เข้าใจภาพในระดับ Semantic ได้ดีกว่า
ข้อจำกัด: ต้องการ Compute สูงมาก ประสิทธิภาพลดลงอย่างมีนัยหาก Dataset มีขนาดเล็ก ในปี 2025 ยังไม่เหมาะกับงาน Real-Time หรือระบบฝังตัว
โมเดลผสมผสาน เช่น Swin Transformer และ ConvNeXt ได้รับความนิยมเพิ่มขึ้นเนื่องจากสามารถดึงข้อดีของทั้งสองฝั่งมารวมกันได้อย่างลงตัว เช่น การใช้ Window-Based Attention ร่วมกับโครงสร้างเชิงลำดับของ CNN
วิวัฒนาการของ Computer Vision จากวิธีเชิง Rule-Based ไปจนถึงการเรียนรู้แบบ End-to-End แสดงให้เห็นถึงศักยภาพของการแทนภาพในระดับลึกซึ้งขึ้นอย่างต่อเนื่อง โดยเฉพาะการมาของ Vision Transformer ที่เปิดประตูสู่แนวทางใหม่ ๆ ในการประมวลผลภาพเชิงสัญลักษณ์และความหมาย (Semantic Understanding) อย่างไรก็ตาม ความสำเร็จของแต่ละเทคนิคยังคงต้องพิจารณาภายใต้กรอบของความเหมาะสมทางบริบทและทรัพยากร
References
Dosovitskiy, A., et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv preprint arXiv:2010.11929
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in neural information processing systems, 25
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D. (1989). Backpropagation applied to handwritten zip code recognition. In D. Touretzky (Ed.), Advances in Neural Information Processing Systems (Vol. 2, pp. 396–404). Morgan Kaufmann
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Vaswani, A., et al. (2017). Attention is all you need. Advances in neural information processing systems, 30


