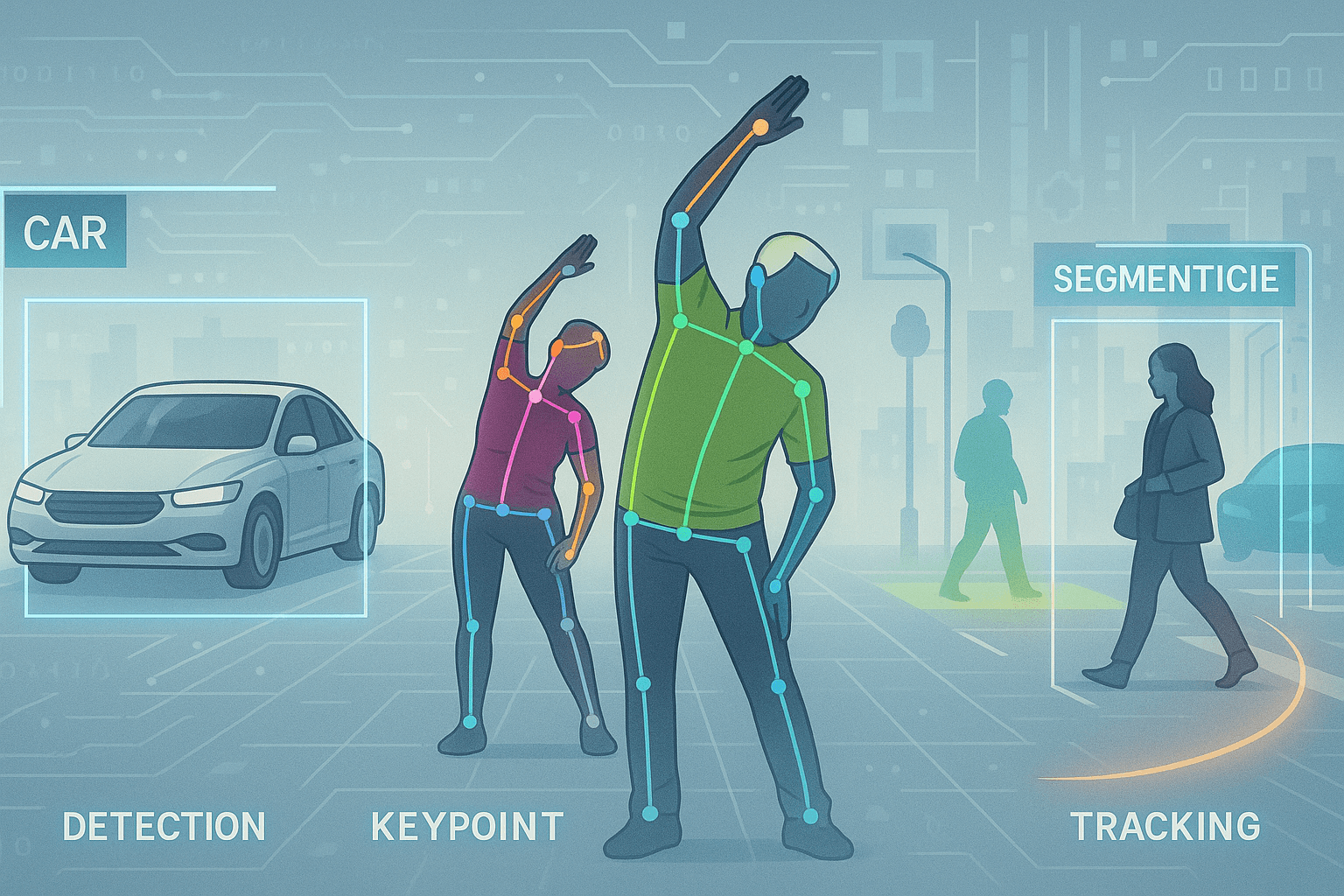
การประมวลผลภาพด้วยคอมพิวเตอร์ (Computer Vision) ได้กลายเป็นหัวใจสำคัญของระบบอัจฉริยะในปัจจุบัน ไม่ว่าจะเป็นยานยนต์ไร้คนขับ การวินิจฉัยทางการแพทย์ การควบคุมคุณภาพในสายการผลิต หรือการวิเคราะห์พฤติกรรมผู้บริโภค ภารกิจหลัก (Vision Tasks) ที่ทำให้ระบบเหล่านี้สามารถเข้าใจภาพได้ครอบคลุม ประกอบด้วย Object Detection, Object Tracking, Segmentation และ Keypoint Detection ซึ่งแต่ละประเภทมีวัตถุประสงค์ วิธีการฝึกโมเดล สถาปัตยกรรม และ Metrics ในการประเมินผลที่แตกต่างกันอย่างมีนัยสำคัญ
1. Object Detection
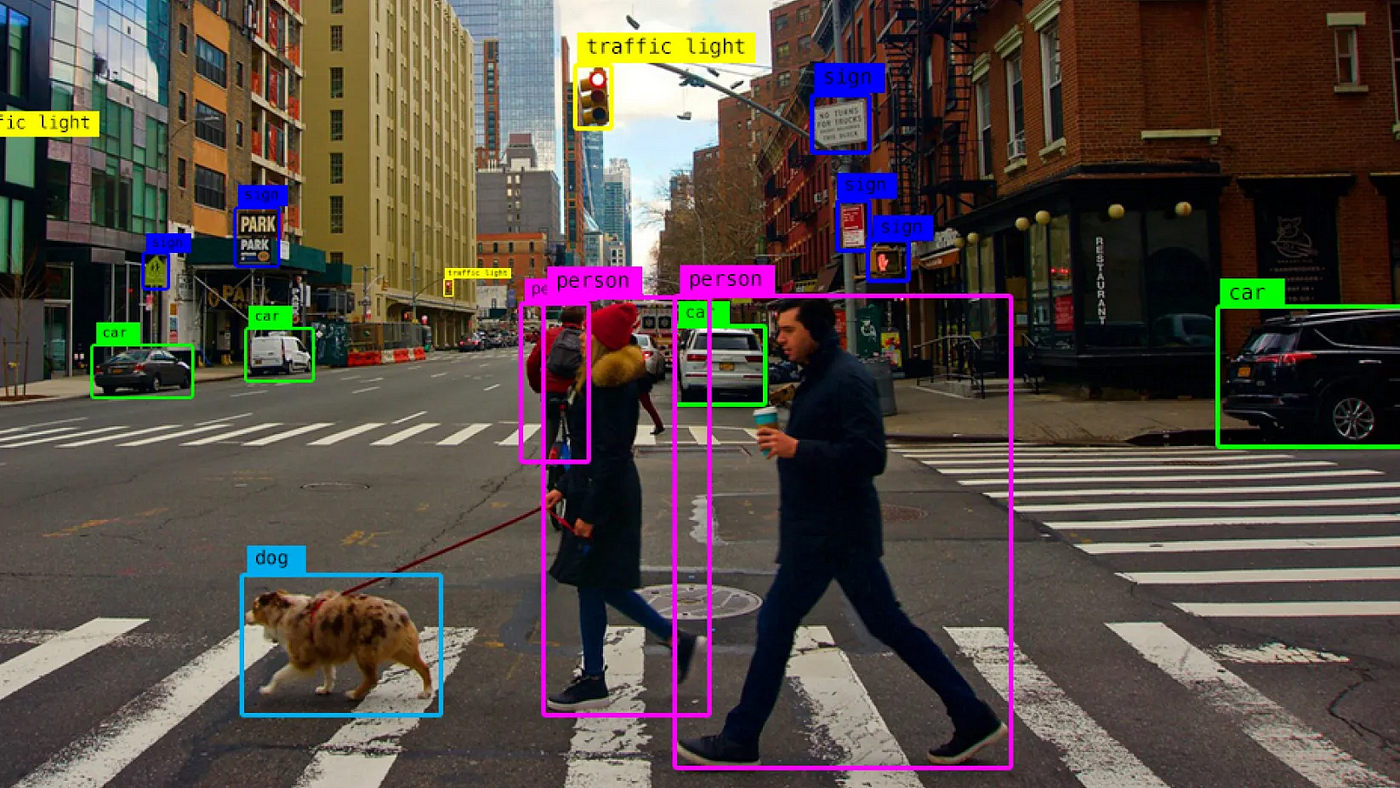
ภาพที่ 1 Object Detection
(ที่มา: https://lopezyse.medium.com/computer-vision-object-detection-with-python-14b241f97fd8)
ข้อมูลที่ใช้ในการฝึกโมเดล: ข้อมูลภาพนิ่งที่ได้รับการ Annotated ด้วย Bounding Boxes และ Class Labels เพื่อระบุ Semantic Category ของวัตถุภายในภาพ โดยชุดข้อมูลมาตรฐานที่นิยม ได้แก่ MS-COCO, Pascal VOC และ Open Images ซึ่งครอบคลุมประเภทวัตถุหลากหลายในบริบทที่ซับซ้อน
ตัวอย่างข้อมูล:
{
"image": "image_001.jpg",
"objects": [
{
"class": "person",
"bbox": [120, 85, 200, 400] // [x_min, y_min, x_max, y_max]
},
{
"class": "dog",
"bbox": [250, 300, 400, 500] // [x_min, y_min, x_max, y_max]
}
]
}สถาปัตยกรรมที่มีบทบาท:
YOLO Series (v5, v7, v8, v11): One-Stage Detectors ที่เน้นความเร็วและประสิทธิภาพ
SSD: โครงสร้างน้ำหนักเบาที่เหมาะกับ Embedded Systems
Faster R-CNN: Two-Stage Detector ที่ให้ความแม่นยำสูงในภาพที่มี Object ซ้อนกันจำนวนมาก
การนำไปประยุกต์ใช้งาน:
ระบบตรวจสอบ PPE สำหรับความปลอดภัยในโรงงานอุตสาหกรรม
ระบบกล้องวงจรปิดอัจฉริยะในงานรักษาความปลอดภัย
ระบบกล้องมือถือที่วิเคราะห์ฉากแบบเรียลไทม์
ตัวชี้วัดการประเมินผล:
mean Average Precision (mAP): ค่าความแม่นยำเฉลี่ยของแต่ละ class เมื่อวัดเทียบกับ IoU ต่าง ๆ โดยค่าที่ใช้กันทั่วไปคือ mAP@0.5 (ตรวจเจอถูกเกิน 50%) หรือแบบละเอียดคือ mAP@0.5:0.95
Intersection over Union (IoU): วัดพื้นที่ที่กล่องที่โมเดลตรวจจับได้ซ้อนกับกล่องจริง (ground truth) หากมี IoU สูงแสดงว่าตรวจจับได้แม่นยำ
Precision-Recall Curve: ช่วยวิเคราะห์ว่าโมเดลตรวจจับแม่นแค่ไหน (precision) และครอบคลุมวัตถุได้มากแค่ไหน (recall) โดยสมดุลของทั้งสองช่วยให้เข้าใจจุดแข็ง-จุดอ่อนของระบบ
2. Object Tracking

ภาพที่ 2 Object Tracking
(ที่มา: https://github.com/RizwanMunawar/yolov7-object-tracking)
ข้อมูลที่ใช้ในการฝึกโมเดล: วิดีโอแบบ Multi-frame ที่ Annotate ด้วย Object ID เพื่อให้โมเดลสามารถติดตามวัตถุข้ามเวลาได้อย่างต่อเนื่อง โดยอาศัยการจับคู่ Features ทั้งด้านรูปลักษณ์และการเคลื่อนไหว
ตัวอย่างข้อมูล:
{
"video_id": "video_001",
"frames": [
{
"frame_index": 1,
"objects": [
{"id": 1, "class": "person", "bbox": [100, 80, 150, 300]},
{"id": 2, "class": "car", "bbox": [200, 250, 350, 400]}
]
},
{
"frame_index": 2, // คนและรถเปลี่ยนตำแหน่งใน Video
"objects": [
{"id": 1, "class": "person", "bbox": [102, 82, 152, 302]},
{"id": 2, "class": "car", "bbox": [205, 255, 355, 405]}
]
}
]
}โดยที่: id คือ ตัวระบุวัตถุเดียวกันในแต่ละเฟรม
โมเดลที่มีความโดดเด่นทางเทคนิค:
Deep SORT: ใช้ Deep Embedding เพื่อจับคู่ Object ID ข้ามเฟรม
ByteTrack: เพิ่ม Robustness ต่อ Detection Score ที่ต่ำ
StrongSORT: เพิ่มคุณภาพ Embedding และ Temporal Modeling
การนำไปประยุกต์ใช้งาน:
การวิเคราะห์การจราจรในเมือง
Retail Analytics
การติดตามผู้เล่นและลูกบอลในกีฬา
ตัวชี้วัดการประเมินผล:
MOTA (Multiple Object Tracking Accuracy): รวมผลของ False Positives, False Negatives และ ID Switches เข้าด้วยกันเพื่อประเมินความแม่นยำของระบบติดตามภาพรวม
IDF1 (Identity F1 Score): ค่าที่วัดว่าระบบสามารถคง ID ของวัตถุแต่ละตัวได้แม่นยำแค่ไหน หากค่า IDF1 ต่ำ แสดงว่าเกิดการสลับตัว (Switch) บ่อย
HOTA (Higher Order Tracking Accuracy): Metric สมัยใหม่ที่ผสมทั้ง Spatial Accuracy และการจับคู่ Temporal อย่างรัดกุม
ID Switches: จำนวนครั้งที่ระบบสับสนระหว่างวัตถุ A กับวัตถุ B ซึ่งแสดงถึงความไม่เสถียรของการติดตาม
3. Segmentation

ภาพที่ 3 Segmentation
(ที่มา: https://github.com/RizwanMunawar/yolov7-object-tracking)
ข้อมูลที่ใช้ในการฝึกโมเดล: Pixel-level Annotation สำหรับ Semantic หรือ Instance Segmentation โดย Semantic Segmentation ให้ Label กับทุกพิกเซลตามหมวดหมู่ ขณะที่ Instance Segmentation แยกแต่ละวัตถุเป็นอิสระกัน แม้จะอยู่ใน Class เดียวกัน
ตัวอย่างข้อมูล:
{
"image": "image_002.jpg",
"annotations": [
{
"id": 1,
"category": "person",
"segmentation": [[104, 78, 108, 90, 115, 102, ...]], // Polygon ของ Mask
"iscrowd": 0
},
{
"id": 2,
"category": "person",
"segmentation": [[200, 80, 205, 92, 210, 105, ...]],
"iscrowd": 0
},
{
"id": 3,
"category": "car",
"segmentation": [[300, 150, 320, 180, 340, 200, ...]],
"iscrowd": 0
}
]
}สถาปัตยกรรมที่มีบทบาท:
Mask R-CNN: เพิ่ม Mask Prediction Branch บน Faster R-CNN
DeepLabV3+: ใช้ Atrous Convolution และ Decoder
Segment Anything (SAM): Zero-Shot Model ที่ตอบสนองต่อ Prompt
U-Net: ใช้กันอย่างแพร่หลายในงานภาพทางการแพทย์
การนำไปประยุกต์ใช้งาน:
ยานยนต์ไร้คนขับ (lane detection, sidewalk)
AR/VR ที่ต้องการแยกพื้นหลังอย่างแม่นยำ
การวิเคราะห์รอยโรคในภาพทางการแพทย์
ตัวชี้วัดการประเมินผล:
mean IoU (mean Intersection over Union): วัดความแม่นยำเชิงพื้นที่ของ Mask ที่ระบบทำนายเมื่อเทียบกับ Mask จริง โดยเฉลี่ยจากหลาย Class
Pixel Accuracy: วัดจำนวนพิกเซลทั้งหมดที่ระบบพยากรณ์ถูกต้อง หารด้วยจำนวนพิกเซลทั้งหมดในภาพ เหมาะกับงานที่ต้องการตรวจจับทุกจุดอย่างแม่นยำ
Dice Coefficient: Metric ที่นิยมใช้ในงานการแพทย์ เพราะเน้นการวัดความซ้อนทับระหว่าง Mask โดยเฉพาะในวัตถุขนาดเล็ก เช่น รอยโรคหรือเนื้องอก
4. Keypoints หรือ Pose Detection

ภาพที่ 4 Pose Detection
(ที่มา: https://pub.towardsai.net/insights-regarding-pose-estimation-c8b37f5df660)
ข้อมูลที่ใช้ในการฝึกโมเดล: Annotation ของจุดสำคัญในวัตถุ เช่น ข้อต่อมนุษย์ (Joints), จุดบนใบหน้า (Facial Landmarks) โดยมีการกำหนด Template ล่วงหน้า เช่น 17 จุดของ COCO Human Pose หรือ 21 จุดของ Hand Pose
ตัวอย่างข้อมูล:
{
"image": "person_001.jpg",
"keypoints": [ // [x, y, v]
[100, 150, 2], // Nose
[95, 140, 2], // Left eye
[105, 140, 2], // Right eye
...
[90, 250, 2] // Left ankle
],
"num_keypoints": 17,
"bbox": [80, 120, 60, 160], // bounding box รอบตัวบุคคล
"category": "person"
}โดยที่: ค่าที่อยู่ใน
คือ พิกัด
คือ visibility (0 = ไม่เห็น, 1 = เห็นแต่ไม่ชัด, 2 = ชัดเจน)
สถาปัตยกรรมที่มีบทบาท:
OpenPose: Bottom-Up Model ที่ Detect จุดก่อน Group
BlazePose: สำหรับการใช้งานบนมือถือโดยเฉพาะ
MediaPipe: Framework ที่ครอบคลุม Face, Pose, และ Hand
HRNet: รักษา Resolution ตลอด Network
การนำไปประยุกต์ใช้งาน:
Gesture Control และ Avatar Mapping
ระบบกายภาพบำบัดระยะไกล
Face Alignment ก่อน Face Recognition
ตัวชี้วัดการประเมินผล:
PCK (Percentage of Correct Keypoints): วัดว่าสัดส่วนของ Keypoints ที่อยู่ภายในระยะที่ยอมรับได้จากตำแหน่งจริง เช่น จุดหัวเข่าที่ระบบทำนายต้องอยู่ห่างจากตำแหน่งจริงไม่เกิน 10% ของความสูงภาพ
OKS (Object Keypoint Similarity): คล้ายกับ IoU แต่ใช้กับ Keypoints โดยคำนวณจากตำแหน่งและความมั่นใจในการตรวจจับแต่ละจุด
AUC (Area Under Curve): วัดคุณภาพโดยรวมของโมเดลเมื่อลองใช้ Threshold หลายระดับในการตัดสินว่า Keypoint ถูกต้องหรือไม่
การออกแบบระบบ Computer Vision ที่มีความสามารถในการทำความเข้าใจโลกจริงอย่างแม่นยำ จำเป็นต้องเลือก Task และโมเดลให้สอดคล้องกับลักษณะของข้อมูล เป้าหมายเชิงระบบ และข้อจำกัดเชิงเทคนิค เช่น ความเร็วในการประมวลผล ขนาดของโมเดล และข้อกำหนดด้านความปลอดภัย
ในระบบกล้องหลายตัวแบบ Real-Time การรักษา Identity Continuity จำเป็นต้องใช้ Object Tracking ที่ Robust ต่อ Occlusion และการเปลี่ยนมุมกล้อง
ระบบวิเคราะห์ท่าทาง ต้องอาศัย Keypoints Detection ที่เสถียรในเชิงเวลา เพื่อประเมินพฤติกรรมผู้ใช้ได้แม่นยำโดยไม่รบกวน
งานด้าน AR หรือการแพทย์ที่ต้องการ Granularity สูง จะได้ประโยชน์จาก Segmentation ที่ละเอียดระดับ Pixel
ความเข้าใจที่ลึกซึ้งในแต่ละ Vision Task ไม่เพียงเป็นรากฐานของการพัฒนาโมเดล แต่ยังเป็นแกนกลางของการบูรณาการความรู้เชิงเทคนิคสู่ระบบอัจฉริยะที่ใช้งานได้จริง
Reference
He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask R-CNN. Proceedings of the IEEE International Conference on Computer Vision (ICCV).
Redmon, J., & Farhadi, A. (2018). YOLOv3: An Incremental Improvement. arXiv preprint.
Wojke, N., Bewley, A., & Paulus, D. (2017). Simple Online and Realtime Tracking with a Deep Association Metric. Proceedings of the IEEE International Conference on Image Processing (ICIP).
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. Medical Image Computing and Computer-Assisted Intervention (MICCAI).


